Поскольку неизвестное распределение ![]() можно описать, например,
его функцией распределения
можно описать, например,
его функцией распределения ![]() , построим по выборке
«оценку» для этой функции.
, построим по выборке
«оценку» для этой функции.
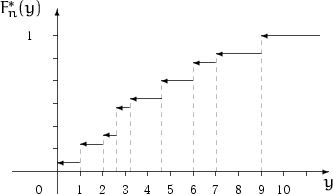
Эмпирической функцией распределения, построенной по выборке
![]() объема
объема ![]() , называется случайная функция
, называется случайная функция
![]() , при каждом
, при каждом ![]() равная
равная
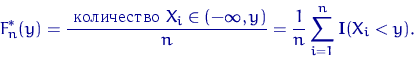
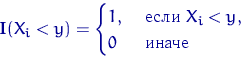
называется индикатором события ![]() . При каждом
. При каждом ![]() это —
случайная величина, имеющая
распределение Бернулли с параметром
это —
случайная величина, имеющая
распределение Бернулли с параметром ![]() .
почему?
.
почему?
Иначе говоря, при любом ![]() значение
значение ![]() , равное истинной вероятности
случайной величине
, равное истинной вероятности
случайной величине ![]() быть меньше
быть меньше ![]() , оценивается
долей элементов выборки, меньших
, оценивается
долей элементов выборки, меньших ![]() .
.
Если элементы выборки ![]() ,
, ![]() ,
, ![]() упорядочить по возрастанию
(на каждом элементарном исходе), получится новый набор случайных
величин, называемый вариационным рядом:
упорядочить по возрастанию
(на каждом элементарном исходе), получится новый набор случайных
величин, называемый вариационным рядом:
![]()
Здесь
![]()
Элемент ![]() ,
, ![]() , называется
, называется ![]() -м членом вариационного ряда или
-м членом вариационного ряда или ![]() -й порядковой статистикой.
-й порядковой статистикой.
Выборка:
![]()
Вариационный ряд:
![]()
|
|
Эмпирическая функция распределения имеет скачки в точках выборки,
величина скачка в точке ![]() равна
равна ![]() , где
, где ![]() — количество
элементов выборки, совпадающих с
— количество
элементов выборки, совпадающих с ![]() .
.
Можно построить эмпирическую функцию распределения по вариационному ряду:
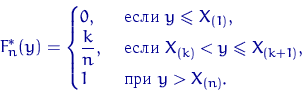
Другой характеристикой распределения является таблица (для дискретных распределений) или плотность (для абсолютно непрерывных). Эмпирическим, или выборочным аналогом таблицы или плотности является так называемая гистограмма.
Гистограмма строится по группированным данным. Предполагаемую
область значений случайной величины ![]() (или область выборочных
данных) делят независимо от выборки на некоторое количество интервалов
(не обязательно одинаковых).
Пусть
(или область выборочных
данных) делят независимо от выборки на некоторое количество интервалов
(не обязательно одинаковых).
Пусть ![]() ,
, ![]() ,
, ![]() — интервалы на прямой, называемые интервалами
группировки. Обозначим для
— интервалы на прямой, называемые интервалами
группировки. Обозначим для
![]() через
через ![]() число элементов выборки,
попавших в интервал
число элементов выборки,
попавших в интервал ![]() :
:
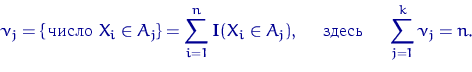 | (1) |
На каждом из интервалов ![]() строят прямоугольник, площадь которого
пропорциональна
строят прямоугольник, площадь которого
пропорциональна ![]() . Общая площадь всех прямоугольников
должна равняться единице. Пусть
. Общая площадь всех прямоугольников
должна равняться единице. Пусть ![]() — длина интервала
— длина интервала ![]() . Высота
. Высота ![]() прямоугольника над
прямоугольника над ![]() равна
равна
Полученная фигура называется гистограммой.
Имеется вариационный ряд (см. пример 1):
![]()
Разобьем отрезок ![]() на 4 равных отрезка. В отрезок
на 4 равных отрезка. В отрезок ![]() попали 4 элемента выборки, в
попали 4 элемента выборки, в ![]() — 6, в
— 6, в
![]() — 3, и в отрезок
— 3, и в отрезок ![]() попали 2 элемента выборки. Строим гистограмму (рис. 2). На рис.
3 — тоже
гистограмма для той же выборки, но при разбиении области на 5 равных
отрезков.
попали 2 элемента выборки. Строим гистограмму (рис. 2). На рис.
3 — тоже
гистограмма для той же выборки, но при разбиении области на 5 равных
отрезков.
| Рис. 2. Пример 2 | Рис. 3. Пример 2 | |
| ||
В курсе «Эконометрика» утверждается, что наилучшим числом
интервалов группировки («формула Стерджесса») является
![]() .
.
Здесь ![]() — десятичный логарифм, поэтому
— десятичный логарифм, поэтому
![]() ,
т.е. при
увеличении выборки вдвое число интервалов группировки увеличивается на 1.
Заметим, что чем больше интервалов группировки, тем лучше. Но, если брать
число интервалов, скажем, порядка
,
т.е. при
увеличении выборки вдвое число интервалов группировки увеличивается на 1.
Заметим, что чем больше интервалов группировки, тем лучше. Но, если брать
число интервалов, скажем, порядка ![]() , то с ростом
, то с ростом ![]() гистограмма не будет приближаться к плотности.
гистограмма не будет приближаться к плотности.
Справедливо следующее утверждение:
Если плотность распределения элементов
выборки является непрерывной функцией, то
при ![]() так, что
так, что ![]() , имеет место поточечная сходимость по вероятности
гистограммы к плотности.
, имеет место поточечная сходимость по вероятности
гистограммы к плотности.
Так что выбор логарифма разумен, но не является единственно возможным.
N.I.Chernova
![\begin{figure}
\unitlength=0.9mm
\begin{picture}
(63.00,35.00)
\put(62.,2.00){\m...
...cc]{\scriptsize 0.1}}
\put(0.00,5.00){\vector(1,0){63}}\end{picture}\end{figure}](img74.gif)