Найдем ОМНК для функций ![]() в ряде частных случаев. Напомним,
что ОМП совпадает с ОМНК почти исключительно в случае нормальности вектора ошибок.
в ряде частных случаев. Напомним,
что ОМП совпадает с ОМНК почти исключительно в случае нормальности вектора ошибок.
Пусть функция ![]() — постоянная,
— постоянная,
![]() — неизвестный параметр. Тогда наблюдения равны
— неизвестный параметр. Тогда наблюдения равны
![]() ,
, ![]() . Легко узнать
задачу оценивания неизвестного математического ожидания
. Легко узнать
задачу оценивания неизвестного математического ожидания ![]() по выборке
из независимых и одинаково распределенных случайных величин
по выборке
из независимых и одинаково распределенных случайных величин ![]() . Найдем ОМНК
. Найдем ОМНК ![]() для параметра
для параметра ![]() :
:
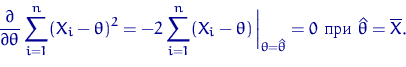
Трудно назвать этот ответ неожиданным. Соответственно, ![]() .
.
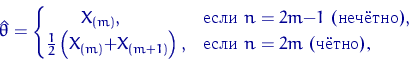
а ОМП для дисперсии равна
![]() . Вместо полусуммы можно брать любую точку отрезка
. Вместо полусуммы можно брать любую точку отрезка ![]() .
.
Рассмотрим линейную регрессию
![]() ,
, ![]() , где
, где ![]() и
и ![]() — неизвестные параметры.
Здесь
— неизвестные параметры.
Здесь ![]() — прямая.
— прямая.
Найдем оценку метода наименьших квадратов ![]() ,
на которой достигается минимум величины
,
на которой достигается минимум величины
![]() . Приравняв к нулю частные
производные этой суммы по параметрам, найдем точку экстремума.
. Приравняв к нулю частные
производные этой суммы по параметрам, найдем точку экстремума.
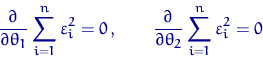
является пара
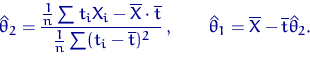
Величина
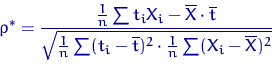
называется выборочным коэффициентом корреляции и характеризует
степень линейной зависимости между наборами чисел
![]() и
и ![]() .
.
Термин «регрессия» появился впервые в работе Francis Galton, "Regression towards mediocrity in hereditary stature" (Journal of the Anthropological Institute V. 15, p. 246-265, 1886).
Гальтон исследовал, в частности, рост детей высоких родителей
и установил, что он «регрессирует» в среднем, т.е.
в среднем дети высоких родителей не так высоки, как их родители.
Пусть ![]() — рост сына (дочери),
а
— рост сына (дочери),
а ![]() и
и ![]() — рост отца и матери.
Для линейной модели регрессии
— рост отца и матери.
Для линейной модели регрессии ![]() Гальтон нашел оценки параметров:
Гальтон нашел оценки параметров:
![]()
а средний рост дочери еще в 1,08 раз меньше.
N.I.Chernova